编译原理中的词法分析作业真的是折磨死我了。熬夜弄了一个不完美的版本。在此总结一下。
首先,我们要清楚地了解到整个程序的逻辑过程为如下几个过程:
- 正则表达式转换NFA
- NFA转换DFA
- DFA简化为最小化DFA
- 使用最小化DFA构建词法分析程序
很好,我们清晰地了解到这几个步骤之后,我们先来看正则表达式转换NFA。
思路如下:
要对输入的正则表达式进行分析,就如同之前学过的通过构建算术表达式的后缀表达式一样,我们需要通过区分正则表达式中符号及非符号,对正则表达式中符号的优先级进行先后的处理,这时,我们可以简单地想到使用栈来对符号和非符号进行存储。于是,得出一下结论:
数据结构:符号栈,NFA栈
然后,让我们进一步对非符号和符号进行分析:
非符号:这个很好分析,所有字母和$\epsilon$及$\varnothing$我们看作是最基本的NFA结构。可以构造如下: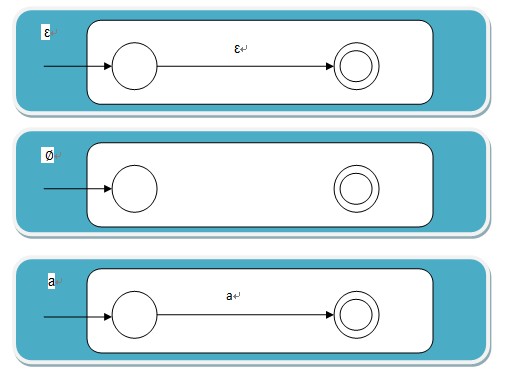
符号:复杂的正则表达式拥有很多不同的运算符号,这里我们只对最基本的几种符号进行分析处理。
如:
“(“,左括号;
“)”,右括号;
“*“,重复符号;
“|”,选择符号;
“.”,连接符号; (P.S: 此符号一般不出现在正则表达式里,但我们在构建NFA的时候要进行判断是否存在连接运算并添加处理)
下面来详细说明一下各符号的处理:
“(“, 左括号。最简单,只需压入符号栈即可。
“)”, 右括号。不需要压入符号栈,但遇到后需要弹出所有在”(“后面压入的运算符号,并进行运算。
“*“,重复符号。不需要压入符号栈,且在运算符号里的优先级最高。所以遇到后可以直接弹出NFA进行运算,再把运算得出的结果压入NFA栈里。
“|”,选择符号。优先级不如连接符号高,在遇到后,需要先将符号栈内比它优先级更高的符号弹出运算。注意,左括号不弹出,即遇到左括号弹出终止。所以这里需要将连接符号和选择符号(从左到右运算,所以优先级也比此符号高)弹出运算后,再将此符号压入符号栈。
“.”,连接符号。由于正则表达式中不会真正出现连接符号,所以我们应该分析在哪个时候添加连接符号。我们可以看出,在符号”)”,”*“后需要判断下一个元素是否为非符号或左括号,然后在其后压入一个连接符号入栈。同理,在非符号后也需要做上述判断和处理。
具体运算细节:
- 连接运算。需要弹出NFA栈中的两个NFA,将一个NFA的end连接到另一个NFA的start,再将新的NFA压入NFA栈内。
- 选择运算。需要弹出NFA栈中的两个NFA,重新分配两个新的节点,作为新的NFA的start和end,然后把新的NFA的start连到两个NFA的start中,两个NFA的end连到新的NFA的end中,再压入NFA栈。
- 闭包运算。需要弹出NFA栈中的一个NFA,然后重新分配两个新节点,作为新NFA的start和end, 然后新的start连接弹出的NFA的start,弹出的NFA的end连接新的end。然后新的start连到新的end的一条空边和旧的end连到旧的start的一条空边。最后把新的NFA压入NFA栈内。
如下图所示: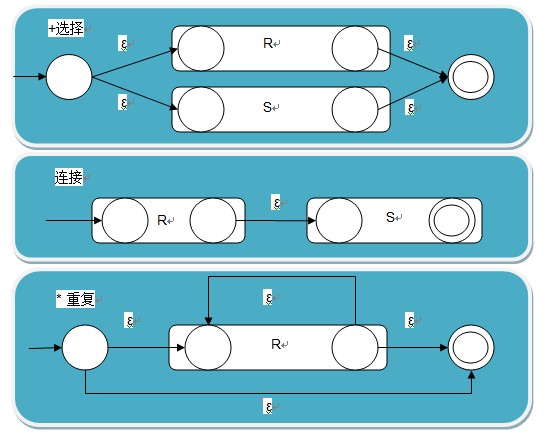
整个程序的具体过程应是如下:
- 用户输入一个正则表达式,用String来进行存储。
- 遍历这个正则表达式,对非符号和符号做上文对应讲述的操作。
- 遍历完毕后,检查符号栈是否为空,若不为空,则弹出所有符号做对应的运算直至符号栈为空。
- 最后NFA栈中唯一的NFA就是所求的NFA。