监督学习是什么?
监督学习指的是我们获得一个数据集,看作输入,同时我们知道正确的答案,看作输出。认为输入和输出之间存在一定的关系。
监督学习被分成了两类问题:
- 回归问题(Regression)
- 分类问题(Classification)
回归问题:在回归问题中,我们试着在一段连续的输出中预测结果。即意味着我们试着将输入变量映射到某些连续函数上。如:预测房价(如下图)。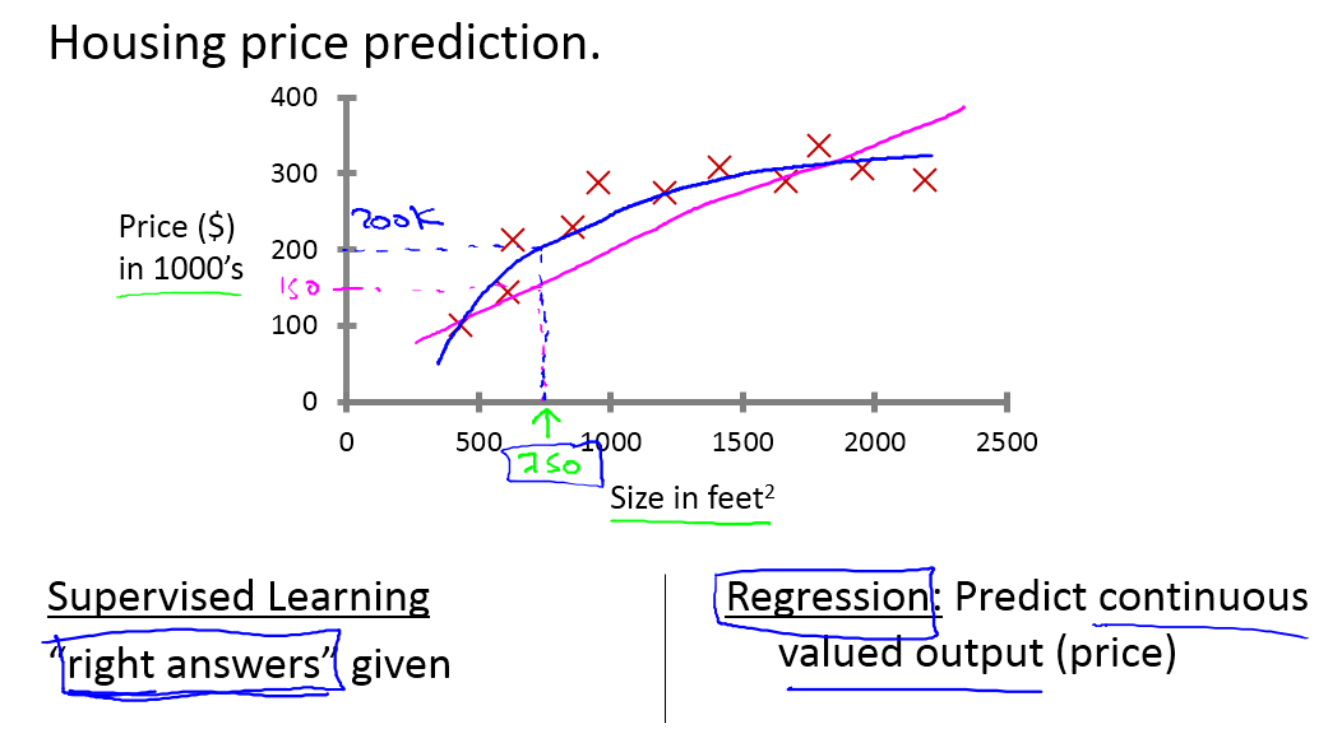
在房价这个例子中,我们给了一系列房子的数据,给定了数据集中每个样本的正确价格,即它们的实际售价来运用学习算法,算出更多的答案,这些答案落在一个连续的区间上,所以看作是回归问题。可以看到图中,我们采用直线和二次方程的曲线来拟合数据。在这个过程中,我们采用了不同的学习算法,当然有一个会显得更加合理,我们先不在此做深入讨论。
分类问题:在分类问题中,我们试着在一些离散的输出中来预测结果。换句话说,我们试着将输入变量映射到离散的分类里。如:推测乳腺肿瘤良性与否(如下图)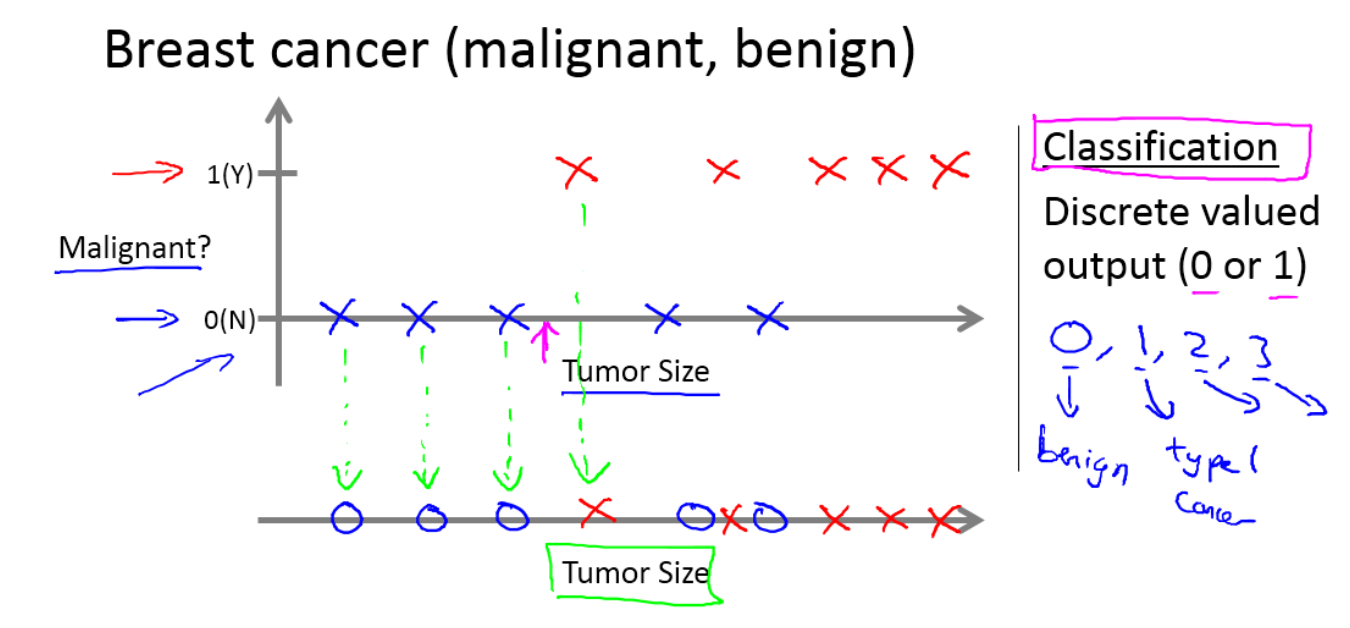
在推测乳腺肿瘤良性与否的例子中,我们给出了肿瘤的大小(横轴)和它们所对应是否为良性的正确答案(纵轴),用以运用学习算法来算出更多的答案,这些答案会落在两个分类里,分别表示恶性肿瘤和良性肿瘤。可以看到图中分类一共只有两类,但在实际中,分类问题的输出可能并不只有两个值。比如说存在着三种乳腺癌,因为我们希望分成三类,所以我们的预测值就会达到三个。
综上所述,回归问题和分类问题的主要区别在与输出是连续还是离散。而监督学习中是通过一组样本及它们所对应的“正确答案”来对数据进行映射处理,从而对数据进行预测得到一段连续或是离散的输出。
无监督学习是什么?
无监督学习中指的是我们获得一个数据集,看作输入,但我们不知道如何操作数据集,无监督学习的本质是在数据中寻找一些结构。
其中无监督学习主要分为了以下问题:
- 聚类问题
- 鸡尾酒宴问题
聚类问题:在没有告知算法标签信息的情况下,通过自动地寻找数据集中的结构,让数据自动地聚类到某些类别当中。如:谷歌新闻、基因聚类(如下图)等。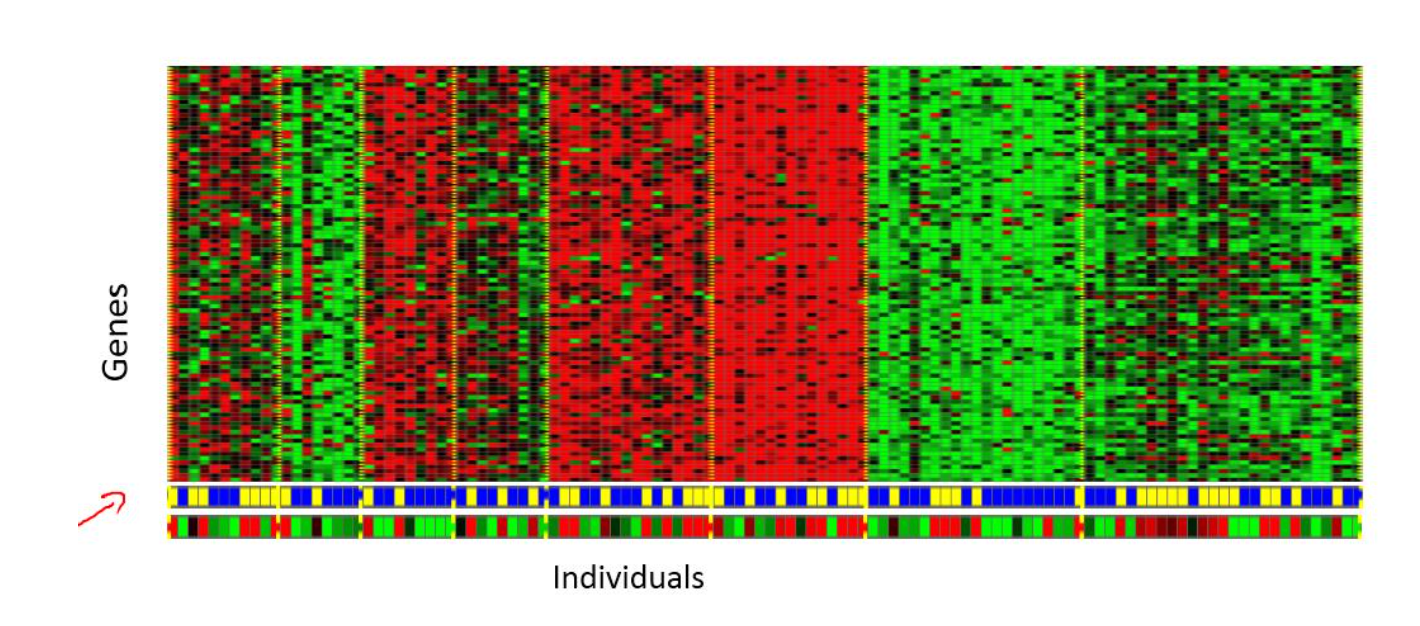
在基因聚类这个例子中,输入是一组不同的个体,我们通过对个体在基因层面上数据的分析即是否表达了某些特定的基因,运行聚类算法,将个体聚类到不同的类别当中。
鸡尾酒宴问题:在宴会房间中,将声音重叠的数据作为输入,运行无监督学习算法,寻找其中的结构,将各种声音相互剥离开来。(如下图)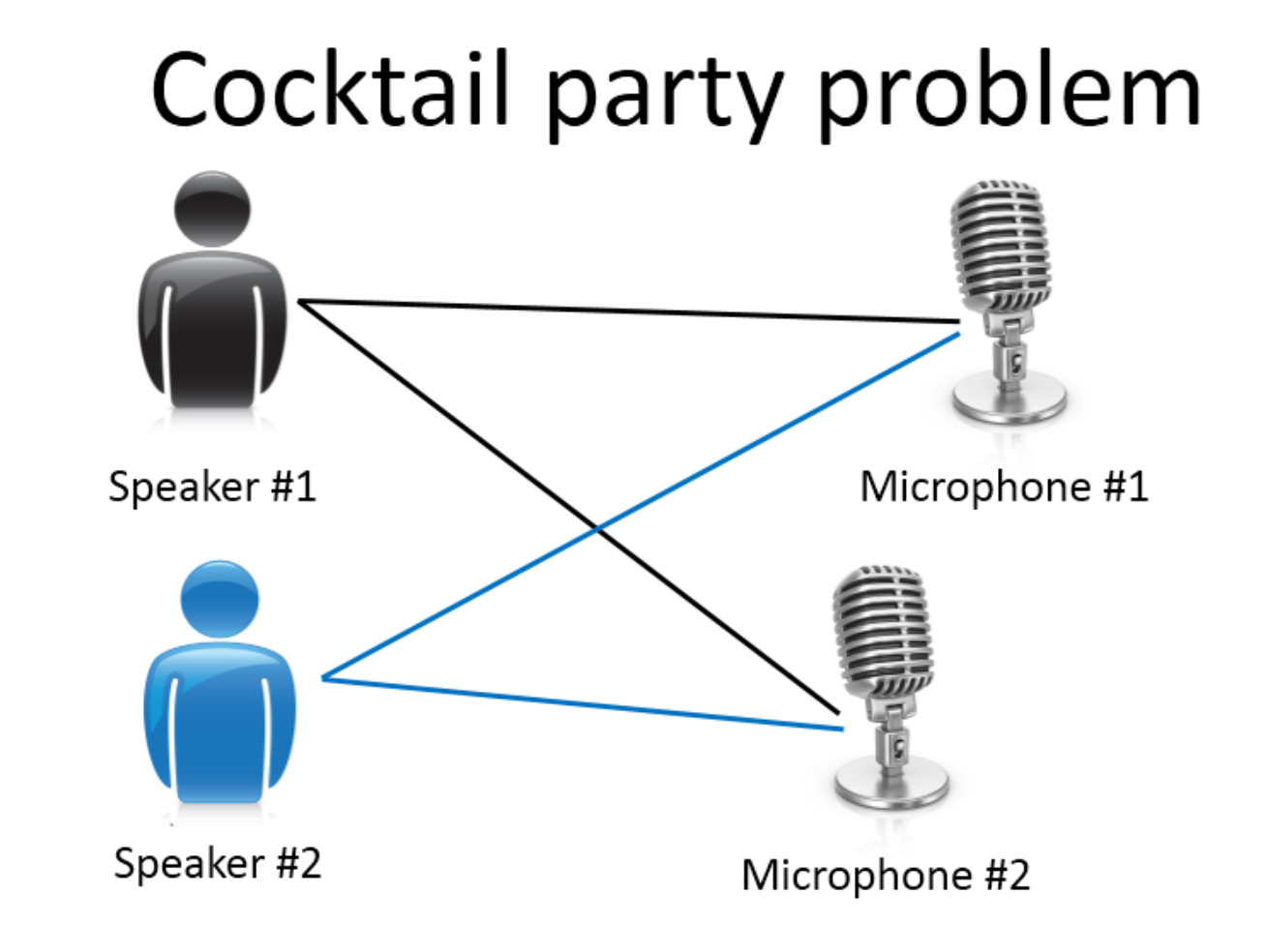
这个例子中是通过了放置两个麦克风,离说话人的距离不同的每个麦克风记录下不同的声音。虽然是同样的说话的两个说话人,听起来像是两份录音被叠加在一起。但算法还是会区分出两个音源。(详细可看维基百科Cocktail party effect)